The C++ language is known for its long compilation times. While that is largely true (compared to many other languages), C++ is also one of the most mature languages out there, with rich tool support. There are now a lot of tools and good practices that can be applied to most C++ projects to help minimize build times.
Goals
When trying to minimize build times, it is good to set your goals. Some reasonable goals are:
- Local incremental builds should be very quick, to allow efficient development iterations (e.g. during debugging).
- Local clean builds should be quick (e.g. to allow fast build times when switching between branches etc).
- CI builds should be fast enough so that integrations to mainline are not delayed.
- CI build & test results should be reported in a timely manner.
In general, build times should be short enough to keep developers focused on the current task (i.e. prevent context switching to distracting business such as XKCD). IMO the following limits are reasonable:
- Maximum time for an incremental local build: 5-10 seconds
- Maximum time for a CI build (including tests etc): 1-2 minutes
Of course these are not hard limits (and you may want to use other limits in your project), but if your build takes longer, there’s value in trying to optimize your build system.
The test case
To benchmark different build optimizations, I selected a decently sized C++ project with a clean CMake-based build system: LLVM (thanks to molsson for the tip!).
Unless otherwise noted, all time measurements are of clean re-builds. I.e. the output build directory was created from scratch, and CMake was re-run using the following configuration:
cmake -DLLVM_TARGETS_TO_BUILD=X86 -DCMAKE_BUILD_TYPE=Release -G [generator] path/to/source
(However, the cmake part is excluded from the timings).
Using this configuration, the build consists of 1245 targets (most of them being C++ compilation units).
The machine I’m using for the benchmarks is a hexa-core Intel i7-3930K (12 hardware threads) Linux machine from 2011 with a couple of decent SSD drives.
About Windows and Mac OS X…
I’m really a Linux person, and the limited Windows experience that I have has only made me conclude that in the world of C++ development, Windows is slightly less mature than Linux (and Mac OS X) in terms of build tools.
In this article I will focus mostly on Linux. However, many concepts are transferable to Windows and Mac OS X, but you may have to find other resources for figuring out the exact details.
The easy wins
Do parallel builds
Are you using all of your CPU cores?
Make sure that you use a parallel build configuration/tool. A simple solution is to use Ninja (rather than Make or VisualStudio, for instance). It has a low overhead, and it automatically parallelizes over all CPU cores in an efficient way.
If you use CMake as your main build tool (you probably should), simply specify a Ninja-based generator (e.g. cmake -G Ninja path/to/source).
If you are limited to using Make, then use the -j flag to do parallel builds (e.g. make -j8).
For VisualStudio, things are not quite as simple, but it is possible to use parallel compilation for VS too. However, if your project is CMake-based, it is actually possible to use Ninja with VS too (just make sure to run cmake in a command prompt with a full VS environment, and select Ninja as the CMake generator). It can be very useful for CI build slaves, for instance.
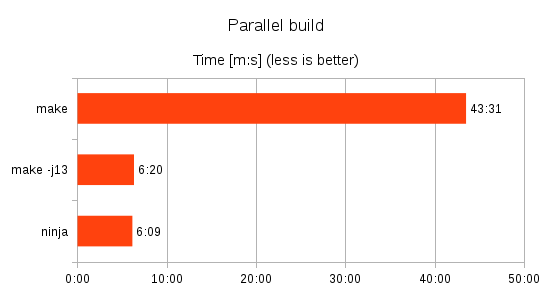
On my six-core machine, using ninja is 7 times faster than regular single-core make.
Use a compiler cache
Using a compiler cache can significantly improve build times. Have a look at:
A compiler cache is especially useful when you make clean builds or switch between branches. In particular, on a build server it can work wonders, where most commits and branches are very similar (lots of re-compilation of the same C++ files over and over).
If you are on Ubuntu, ccache is very simple to install and activate:
sudo apt install ccache export PATH=/usr/lib/ccache:$PATH
(Also add the latter line to your .bashrc, for instance).
Now, when you run CMake it will automatically pick up ccache as your compiler (instead of GCC or Clang, for instance).
Make sure to place the compiler cache on a fast SSD drive.
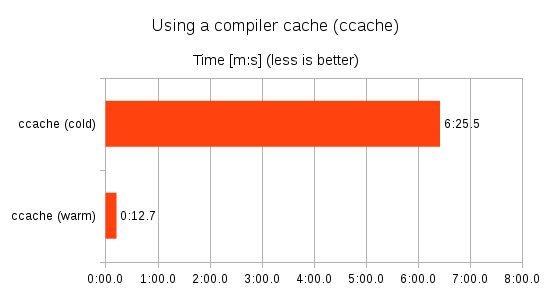
The benchmarks above show the effect of using ccache: The second build (“ccache (warm)”) is 30 times faster than the first build (“ccache (cold)”).
Use a fast linker
In large projects the linking step can be a big bottleneck, especially for incremental builds. To make things worse, the linking step is single threaded, so throwing more CPU cores at it will not help.
If you are on an ELF system (such as Linux) you should know that there is a faster alternative than the default GNU linker, and that is the gold linker.
Here is a simple piece of code for your CMake project that activates the gold linker when possible (I forgot where I found it):
if (UNIX AND NOT APPLE)
execute_process(COMMAND ${CMAKE_C_COMPILER} -fuse-ld=gold -Wl,--version ERROR_QUIET OUTPUT_VARIABLE ld_version)
if ("${ld_version}" MATCHES "GNU gold")
set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} -fuse-ld=gold -Wl,--disable-new-dtags")
set(CMAKE_SHARED_LINKER_FLAGS "${CMAKE_SHARED_LINKER_FLAGS} -fuse-ld=gold -Wl,--disable-new-dtags")
endif()
endif()
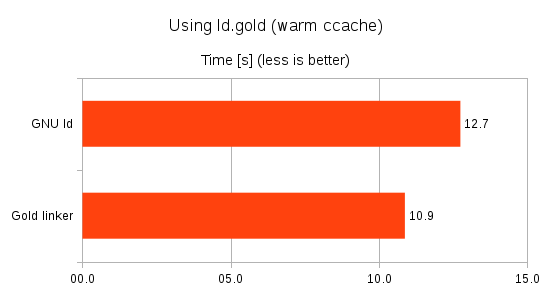
In this case the gold linker saved about 15% in total compared to the default linker.
For incremental builds, the difference is usually even more pronounced (since linking constitutes the lion’s share during incremental builds).
Do distributed builds
It can also help to do distributed builds (i.e. let several computers in a fast LAN work on the same build).
A tool that is free and easy to set up on Linux is icecc/icecream. If 10-20 developers in a LAN install icecc, you have a formidable compile farm!
Provided that the network and the client disks are fast enough, distributed compilation can be several times faster than local compilation. Another nice thing about icecc is that it is polite about client scheduling, and will only use available CPU time (so if a client is already doing CPU heavy work it will not be used for compilation).
Icecc can also be combined with ccache. To use both (provided that iceccd and icecc-scheduler are up and running), you can do this on Ubuntu:
export PATH=/usr/lib/ccache:/usr/lib/icecc/bin:$PATH
…and then run CMake as usual. Note: When running ninja (or make), add more jobs than you would normally do. For instance, in a cluster of 10 machines each with 8 hardware threads, run ninja -j80 (or so).
Unfortunately I do not have access to a rich icecc cluster, but I added a couple of laptops to the LAN to get some extra cores. I didn’t expect any miracles, given that the laptops only added six hardware threads in total (2 + 4), and were lower specced in general.
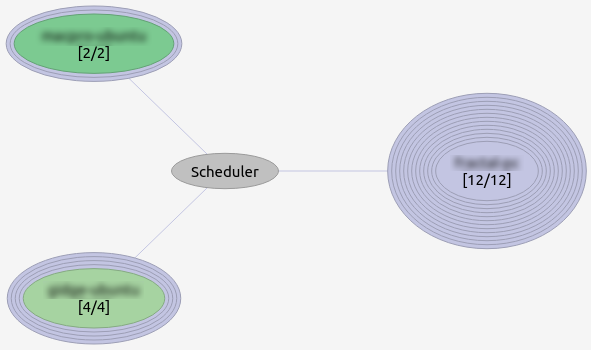
The total compile time was reduced by about 30% (which is quite OK, given the circumstances).
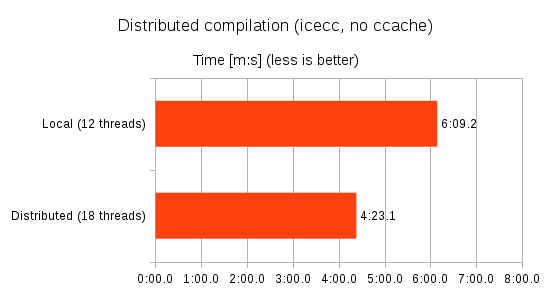
Of course, with a proper cluster (more and better machines), the gains can be manyfold.
A word on CMake…
For most developers, the time it takes to run CMake is not really an issue since you do it very seldom. However, you should be aware that for CI build slaves in particular, CMake can be a real bottleneck.
For instance, when doing a clean re-build of LLVM with a warm CCache, CMake takes roughly 50% of the total build time!
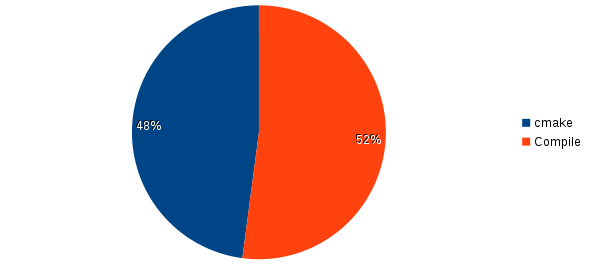 This figure will of course vary between projects, but in my experience it is not uncommon for CMake to take up the majority of the time during a clean re-build.
This figure will of course vary between projects, but in my experience it is not uncommon for CMake to take up the majority of the time during a clean re-build.
With this in mind, make sure to keep an eye on the time it takes to run CMake for your project (and optimize whenever necessary).
A word on CI tests…
When build times have been brought down to a minimum, watch out for other parts of your CI process that may be consuming too much time.
As a rule of thumb, many CI tests (such as unit tests and linter checks) can be parallelized too. For instance, if you are using ctest, don’t forget to use the command line option -j to run unit tests in parallel.
Hardware
Hardware is cheap! Joel Spolsky gives some great arguments for using top notch hardware in his 12 Steps To Better Code (see point 9).
Developer machines
If you are not already using state of the art hardware, upgrading your machines is a simple step to reduce build times. Make sure that you have:
- Fast SSD drives.
- Many CPU cores.
- Lots of fast RAM (the more cores you have, the more RAM you need).
Compilation performance scales surprisingly well with every added CPU core.
Build slaves
Since CI build slaves will typically do full builds (as opposed to incremental builds, that developers do more often), it can pay off even more to use great hardware for the build slaves. Also, if build jobs tend to get queued up (i.e. if slaves are busy), a simple solution is to add more build slaves.
You may also consider adding dedicated clients for distributed compilation.
Working the code
Of course the structure of your code base can have a huge effect on the total build time.
Improving the build times further may require you to refactor your code significantly, which is a grand subject in itself (consider consulting relevant code refactoring resources). However, the good news is that many things that improve code quality also improve build times (and vice versa), so it is an investment that pays off in more than one way.
When optimizing your code base for improved build times, the main concern is C++ includes.
The more dependencies you have, and the deeper your #include depth is, the worse your build times will be. This is partially because using many include files add to the total preprocessing and compilation time for each compilation unit, but it also means that more compilation units are affected by changes in a single header file (and thus require re-compilation).
Some good practices are:
- Include what you use! Make sure that you do not include headers that you do not use.
- There’s a great tool that may help: IWYU.
- With CMake 3.3+, you can even get warnings every time you build your code.
- Avoid the “include everything” pattern. Being specific about what you use is much better than having an “everything.h” include file.
- Use forward declarations where appropriate.
- Use include guards (modern compilers are optimized to ignore multiple inclusions of header files with include guards).
- Don’t include things in the header (.h file) that can be included in the C++ definition (.cpp file) instead.
- Structure your code in modules.
- Differentiate between interface and implementation. Only expose interface headers between modules.
- A good rule of thumb (use with common sense):
- An interface header should deal mainly with declarations that provide storage sizes and method signatures.
- Implementation specific details should be hidden from the interface headers (consider using something like the Pimpl idiom if necessary).
- Use third party dependencies sparingly, especially in interface headers.
- When possible, put a thin abstraction layer around third party dependencies to avoid polluting the code base with third party types.
The intrusive tricks
There are some more tricks that you can use, but they are fairly intrusive, and should be used as a last resort (IMO).
Unity builds
The idea of unity builds is quite simple: Instead of compiling each C/C++ file (.c, .cpp, .cc, …) into a separate object file (.o, .obj), several C/C++ files are compiled at once. The advantages are that there is less overhead in the compiler pipeline, and include files get read and compiled fewer times, which translates to shorter builds times.
For instance, if you have a module (e.g. a static library) that is built from foo1.cpp, foo2.cpp, foo3.cpp, …, fooN.cpp, you would create a file, e.g. called foo-unity.cpp, that includes all the C++ files:
#include "foo1.cpp" #include "foo2.cpp" #include "foo3.cpp" ... #include "fooN.cpp"
And the module/library will depend on this unity file instead of each individual C++ file.
There are a few problems with unity builds though:
- It may not improve build times for incremental builds (in fact, it may make it worse).
- It requires a modified (usually custom) build system.
- C++ files that are part of a unity build must not “leak” local symbols. I.e. static functions, macros etc must use names that are unique for the entire module, not just the C++ file.
- It may counteract other optimization techniques, such as parallel and distributed builds.
Precompiled headers
Another technique that can reduce build times is to use precompiled headers. They are especially useful if you depend on third party libraries that have complex, template heavy headers.
Just like unity builds, however, they are intrusive (i.e. require you to make special arrangements in your code and build system). Furthermore the support for precompiled headers is platform and compiler specific, which makes it especially tricky if you are working on a multi-platform project.
Conclusion
By applying some fairly simple measures, the complete rebuild of a C++ project can go from about an hour (naive single-threaded compilation) to just a few seconds (fully parallelized and cached)!
Since long build times can be a real productivity killer (and it can hurt software quality), any time spent on optimizing the build system is time well spent.
I still remember how surprised I was when I first saw the output of “cpp hello.cc | wc -l” for a hello world program written using std::cout.
Yay! I got 17881 lines (with GCC 4.9.2)!! Another interesting exercise is to list the includes:
g++ -c -o /dev/null -H hello.ccNice collection of the techniques. I recommend mentioning unity build in the Working the code section.
I added a section on unity builds.
For CMake projects, you can avoid having to add ccache to your PATH by using launchers, as explained in the following article:
https://crascit.com/2016/04/09/using-ccache-with-cmake/
Sorry, to be more accurate, the article shows how to use ccache without having to assume ccache is installed with symlinks that shadow the real compiler commands. This can be useful when ccache has to be provided under a local account rather than system-wide, or if the system-wide install doesn’t come with such symlinks.
> CMake takes roughly 50% of the total build time!
Have you checked out Meson ( http://mesonbuild.com ) ? After I started to use CMake more seriously almost two years ago now I started to dislike it with a passion, looked around for alternatives and found Meson.
Much nicer DSL (not turing complete, woho!), supposedly faster ( https://github.com/mesonbuild/meson/wiki/Simple%20comparison ), tries to do “the right thing ™” by default (as opposed to CMake) etc.
I now use it in all my private projects. Only downsides I have found so far is that:
– Most IDE:s does not have the same level of support for it as CMake (though if you can specify build command manually in your IDE, it is often good enough).
– It is also a young project so it is lacking a bit in maturity. Though it makes up for it a lot by having a very responsive maintainer (quick turn around on pull requests/issues) and expanding commnunity (e.g. GNOME will probably migrate to it soon and a couple of Freedesktop components have started looking in to using it).
– Documentation is lacking a bit but it is getting better and there are a lot of tests etc that you can search through to look for examples on how to do things.
I have also not used it on Windows/Mac but I know that GStreamer will probably switch to it soon and use it to build on all systems.
Thanks for mentioning it. I know about Meson, and I’m waiting for an opportunity to try it out. I really like the idea and the design. My only concern is about 3rd party libs support and IDE support, but for a smaller/new project that is not an issue for me.
Great article.
You might also like to try out Zapcc – a fast C++ compiler (https://www.zapcc.com)
Zapcc is a drop-in replacement for clang/gcc and designed to accelerate full build as well as incremental build, without compromising generated code quality.
Great Article
For Visual Studio, you can try Stashed ( https://stashed.io ) which is easier to setup than ccache or clcache.
Hello, Does having fasters RAMs like DDR4 at 3200MHz will help reducing build time or one should focus on have large RAM size only?
I have not benchmarked that particular aspect, but my guess is that faster ram would have less of an effect than a faster CPU or a faster SSD. It really comes down to what the bottlenecks are in your build process. Provided that the build system is perfectly parallelized, cached etc, the usual hardware bottlenecks are: 1) Too few CPU cores, 2) Too slow hard-drive(s) 3) Too little RAM (the more cores & parallel processes, the more RAM you need).
For fast CI CMake builds you should cache the CMake platform introspection checks. For how to do this have a look at: https://github.com/cristianadam/cmake-checks-cache
Thanks a lot! Really nice collection of techniques. I was not aware about the golden linker and the cmake unused include detector.
Why do you need the “-Wl,–disable-new-dtags” options for the linker?
I just copy-paste:d it, so I don’t know really.
Has anyone here tried IncrediBuild acceleration for c++ builds? It’s the best and seamless solution for speeding up c++ builds, and they offer a free version as well! http://www.incredibuild.com