One of the things that is overlooked in many Git based projects is the value of a linear commit history. In fact, many tools and guidelines discourage Git workflows that aim for a linear history. I find this sad, since a tidy history is very valuable, and there is a straight forward workflow that ensures a linear history.
Linear vs non-linear history
A linear history is simply a Git history in which all commits come after one another. I.e. you will not find any merges of branches with independent commit histories.
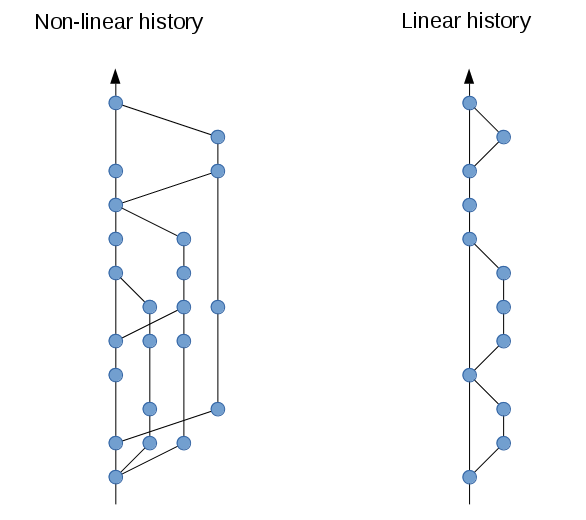
Why do you want a linear history?
Besides being tidy and logical, a linear history comes in handy when:
- Looking at the history. A non-linear history can be very hard to follow – sometimes to the point that the history is just incomprehensible.
- Backtracking changes. For instance: “Did feature A get introduced before or after bugfix B?”.
- Tracking down bugs. Git has a very neat function called Git bisect, which can be used to quickly find which commit introduced a bug or regression. However, with a non-linear history, Git bisect becomes hard or even impossible to use.
- Reverting changes. Say that you found a commit that caused a regression, or you want to remove a feature that was not supposed to go out in a specific release. With some luck (if your code has not changed too much) you can simply revert the unwanted commit(s) using Git revert. However, if you have a non-linear history, perhaps with lots of cross-branch merges, this will be significantly harder.
There are probably another handful of situations in which a linear history is very valuable, depending on how you use Git.
Point is: The less linear your history is, the less valuable it is.
Causes of a non-linear history
In short, every merge commit is a potential source of a non-linear history. However, there are different kinds of merge commits.
Merge from a topic branch into master
When you are done with your topic branch and want to integrate it into master, a common method is to merge the topic branch into master. Perhaps something along the lines:
git checkout master git pull git merge --no-ff my-topic-branch
A nice property with this method is that you preserve the information about which commits were part of your topic branch (an alternative would be to leave out “–no-ff”, which would allow Git to do a fast-forward instead of a merge, in which case it may not be as clear which of the commits actually belonged to your topic branch).
The problem with merging to master arises when your topic branch is based on an old master instead of the latest tip of master. In this case you will inevitably get a non-linear history.
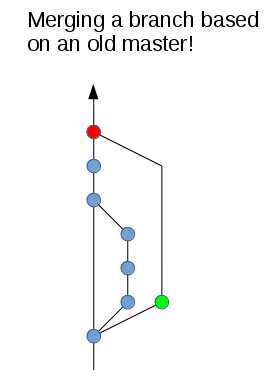
Whether or not this will be a common problem or not largely depends on how active the Git repository is, how many developers are working concurrently, etc.
Merge from master into a topic branch
Sometimes you want to update your branch to match the latest master (e.g. there are some new features on master that you want to get into your topic branch, or you find that you can not merge your topic branch into master because there are conflicts).
A common method, which is even recommended by some, is to merge the tip of master into your topic branch. This is a major source of non-linear history!
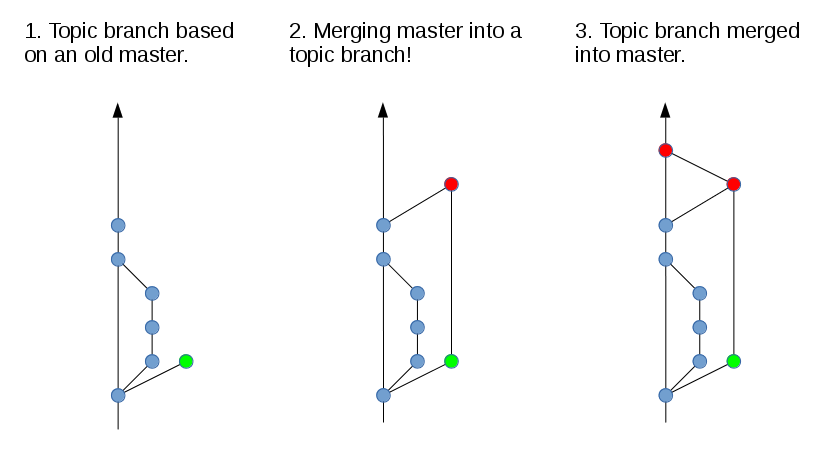
The solution: Rebase!
Git rebase is a very useful function that you should use if you want a linear history. Some find the concept of rebasing awkward, but it’s really quite simple: replay the changes (commits) in your branch on top of a new commit.
For instance, you can use Git rebase to change the root of your topic branch from an old master to the tip of the latest master. Assuming that you have your topic branch checked out, you can do:
git fetch origin git rebase origin/master
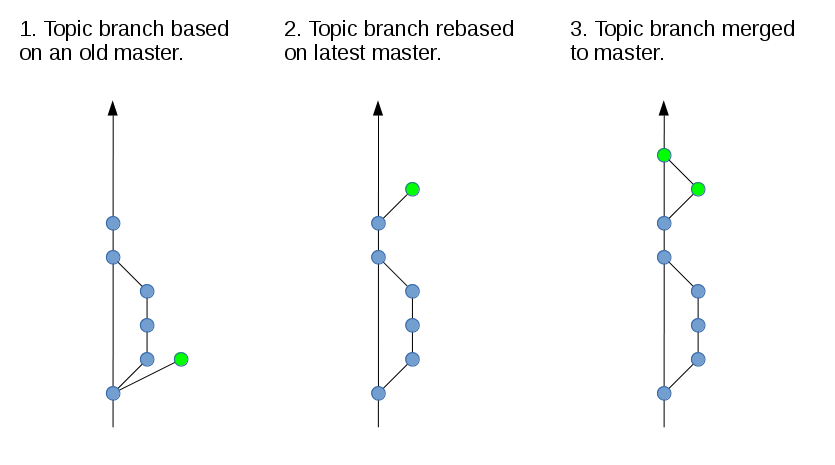
Note that the corresponding merge operation would be to merge the tip of master into your topic branch (as depicted in the previous figure). The resulting contents of the files in your topic branch would be the same, regardless if you do a rebase or a merge. However, the history is different (linear vs non-linear!).
This sounds all fine and well. However, there are a couple of caveats with rebase that you should be aware of.
Caveat 1: Rebase creates new commits
Rebasing a branch will actually create new commits. The new commits will have different SHA:s than the old commits. This is usually not a problem, but you will run into trouble if you rebase a branch that exists outside of your local repository (e.g. if your branch already exists on origin).
If you were to push a rebased branch to a remote repository that already contains the same branch (but with the old history), you would:
- Have to force push the branch (e.g.
git push --force-with-lease), since Git will not allow you to push a new history to an existing branch otherwise. This effectively replaces the history for the given remote branch with a new history. - Possibly make someone else very unhappy, since their local version of the given branch no longer matches the branch on the remote, which can lead to all sorts of trouble.
In general, avoid overwriting the history of a branch on a remote (the one exception is to rewrite the history of a branch that is under code review – depending on how your code review system works – but that is a different discussion).
If you need to rebase a branch that is shared with others on a remote, a simple workflow is to create a new branch that you rebase, instead of rebasing the original branch. Assuming that you have my-topic-branch checked out, you can do:
git checkout -b my-topic-branch-2 git fetch origin git rebase origin/master git push -u origin my-topic-branch-2
…and then tell people working on my-topic-branch to continue working on my-topic-branch-2 instead. The old branch is then effectively obsolete, and should not be merged back to master.
Caveat 2: Resolving conflicts in a rebase can be more work than in a merge
If you get a conflict in a merge operation, you will resolve all the conflicts as part of that merge commit.
However, in a rebase operation, you can potentially get a conflict for every commit in the branch that you rebase.
Actually, many times you will find that if you get a conflict in a commit, you will encounter related (very similar) conflicts in subsequent commits in your branch, simply because commits in a topic branch tend to be related (e.g. modifying the same parts of the code).
The best way to minimize conflicts is to keep track of what’s happening in master, and avoid letting a topic branch run for too long without rebasing. Dealing with small conflicts up front every now and then is easier than to handle them all in one big happy conflict mess at the end.
Some warnings for GitHub users
GitHub is great at many things. It’s fantastic for Git hosting, and it has a wonderful web interface with code browsing, nice Markdown functionality, Gist, etc.
Pull requests, on the other hand, has a few functions that actively thwarts linear Git history. It would be very welcome if GitHub actually fixed these issues, but until then you should be aware of the shortcomings:
“Merge pull request” allows non-linear merges to master
It can be tempting to press the green, friendly looking “Merge pull request” button to merge a topic branch into master. Especially as it reads “This branch is up-to-date with the base branch. Merging can be performed automatically”.

What GitHub is really saying here, is that the branch can be merged to master without conflicts. It does not check whether or not the pull request branch is based on the latest master.
In other words, if you want a linear history, you need to make sure that the pull request branch is rebased on top of the latest master yourself. As far as I can tell, no such information is available via the GitHub web interface (unless you’re using “protected branches” – see below), so you need to do it from your local Git client.
Even if the pull request is properly rebased, there is no guarantee that the merge operation in the GitHub web interface will be atomic (i.e. someone may push changes to master before your merge operation goes through – and GitHub will not complain).
So really, the only way to be sure that your branches are properly rebased on top of the latest master is to do the merge operation locally and push the resulting master manually. Something along the lines:
git checkout master git pull git checkout my-pullrequest-branch git rebase master git checkout master git merge --no-ff my-pullrequest-branch git push origin master
If you’re unlucky and someone manages to push changes to master between your pull and push operations, your push operation will be denied. This is a good thing, however, since it guarantees that your operation is atomic. Just git reset --hard origin/master and repeat the above steps until it goes through.
Note: Respect your project guidelines w.r.t. code reviewing and testing. E.g. if you’re running automatic tests (builds, static analysis, unit tests, …) as part of a pull request, you should probably re-submit your rebased branch (either using git push -f, or by opening a new PR) rather than just updating the master branch manually.
Protected branches functionality encourages merges from master
If you are using protected branches and status checks in your GitHub project, you actually get protection from merging a pull request branch into master unless it is based on the latest master (I think the rationale is that status checks performed on the PR branch should still be valid after merging to master).
However… If the pull request branch is not based on the latest master, you are presented with a friendly button called “Update branch”, with the text “This branch is out-of-date with the base branch. Merge the latest changes from master into this branch”.

At this point, your best option is to rebase the branch locally and force-push it to the pull request. Assuming that you have my-pullrequest-branch checked out, do:
git fetch origin git rebase origin/master git push -f
Unfortunately, GitHub pull requests do not play well with force pushes, so some of the code review information may get lost in the process. If that is not acceptable, consider creating a new pull request (i.e. push your rebased branch to a new remote branch and create a pull request from the new branch).
Conclusion
If you care about a linear history:
- Rebase your topic branch on top of the latest master before merging it to master.
- Don’t merge master into your topic branch. Rebase instead.
- When sharing your topic branch with others, create a new branch whenever you need to rebase it (
my-topic-branch-2,my-topic-branch-3, …). - If you’re using GitHub pull requests, be aware:
- The “Merge” button does not guarantee that the PR branch is based on the latest master. Rebase manually when necessary.
- If you’re using protected branches with status checks, never press the “Update branch” button. Rebase manually instead.
If you don’t care too much about a linear Git history – happy merging!
Wishlist for GitHub
To you fine people working at GitHub: Please add support for rebase workflows in pull requests (these could be opt-in repository options).
- Add the possibility to disable the Merge button/operation in pull requests if the branch is not based on the latest master (this should not require the use of status checks).
- Add a “Rebase onto latest master” button. In many cases this should be a conflict free operation that can easily be done via the web interface.
- Preserve pull request history (commits, comments, …) after a rebase / force push.
[EDIT: I did a follow-up article about different Git history models: Git history: work log vs recipe]
Uh, you don’t have a linear history there.
A linear history is achieved when people grab a cluestick and do “git rebase” and avoid “git merge”.
Then it looks like this: HEAD-> *—*—*—*—*—* …
One LINE, hence LINEAR.
Kaz, I think it’s a matter of taste (and choice of words). In terms of history traversal, you generally get the same values from a purely linear history (i.e. always rebase, never merge) as you do when you allow merges from rebased branches into master (there is still a well defined commit order).
In the latter case (as described in this post) you get the added value of topic branch separation, which IMO is quite useful.
Regarding semantics, it’s worth noting that GitLab already supports this workflow and calls it “semi-linear history”, so it would probably be worth adopting that designation to ensure that discussion about this strategy doesn’t get mixed up with that on other workflows, such as the pure linear one.
In fact, it would be helpful to make this distinction in the post itself — I took the liberty to make a variant of the diagram that includes the pure linear workflow, which allows these strategies to be quickly compared and understood at a glance: http://imgur.com/g3hhD2w
Feel free to use that image in the post if you feel it has value 🙂
While article describes good practices very well, there are two issues, that bothers me. First if those is use of ‘-f’ or ‘–force’ flag to git push. The correct flag is ‘–force-with-lease’, which requires use to fetch changes first, giving him opportunity to notice other users pushes that otherwise might get overwritten. There’s no valid reason to use -f since the introduction of (unfortunately longer) flag –force-with-lease around git 1.8.
Second issue is use of git pull, while git fetch/git merge (or rebase) should be preferred. It may be a matter of taste, but I find git pull a bad practice.
Good points! I was not aware of –force-with-lease, so I’ll have to familiarize myself with it. Regarding pull, you’re right that you should be careful with it. I like to keep master clean and up to date with origin/master at most times, in which case git pull works well for master.
I updated the article in a couple of places to reflect your ideas.
Personally, I find this to be the equivelant of faking history.
:PHowever, I do see the advantages of this, and they seem to outweigh the moral disadvantage. But still, it feels… slightly wrong.
I like to think of it more in terms of serving the correct history to the posterity. More in Git history: work log vs recipe
GitHub now has status checks for base branches like master.
https://github.com/blog/2051-protected-branches-and-required-status-checks
Also, GitHub technically does keep PR histories, but not in git.
Example: https://github.com/tkadlec/WPOStats/pull/4
Status checks make things better (except for the merge-master-to-pr-branch button). I’m currently investigating a WebHook + status check combination that can enforce a rebased branch on GitHub (still no rebase button in the web interface though).
Some of the PR history is lost when you do a force push. In particular I believe that old commits and comments on old commits disappear. There are other systems that can deal with this just fine, see https://critic-review.org/r/342 for instance.
Thanks for the article, I did learn a lot, yet still have a big problem with non-linear history on git. I’m one of those who really recommend merging the tip of master to a feature branch in my organization. Mostly because (I would love to be WRONG in one of those issue, PLEASE correct me if I’m wrong)
1) Our feature branches marked with a specific ticket id say: feat/ticket-337, generating feat/ticket-377-2 branch and ״ …then tell people working on my-topic-branch to continue working on my-topic-branch-2 instead״ is kinda problematic. A) It will break integration issue trackers B) By the time you will work on merge/rebase master already moved forward with new commits and you may have to repeat the process.
2) Most features branches are been worked on for longer then 1 day. I’m urging my team to push their changes as often as possible A) for distributed backup B) Code Review by someone else in the team C) In case of a big change / refactoring, depended tasks may branch out of the feature branch while it’s still been worked on.
3) Sometimes those branches are been worked on by more then one developer. In this case, it’s next to impossible to avoid non-linear history (or just too much of a hassle).
In my mind, non-linear history is fundamentally a git issue and not a workflow issue. In big teams it’s really difficult to avoid
Some thoughts:
1 A) This seems mostly related to issue tracker integration (what are the limitations? how is it configured?). You can device other naming schemes, e.g. feat/ticket-337/1, feat/ticket-337/2, feat/ticket-337/3 (just make sure that you ALWAYS put the /1 on the first branch, just in case that you need to make a /2 later).
1 B) You will typically not do a lot of rebases during shared development (maybe a couple of times per week or so, or even less, depending on your code base etc). Once you get into the integration phase, it’s usually more natural to have a single person do the rebasing etc, in which case you can work with a single branch.
2 A) I’m not sure that this is a good practice. There are other ways to do backup. The point of Git really is that it’s distributed and as long as your branches are local you have a lot of flexibility and can work more efficiently than when you’re pushing to a central repo.
2 C) Should not be a problem. One way to do it: 1) Branch feat/ticket-123/1 off from an existing feature branch. 2) Do commits on your new branch. 3) Once the original feature branch has been integrated to master, create a new branch feat/ticket-123/2 from master and cherry-pick the commits from feat/ticket-123/1 into the new branch (if you used git rebase instead, you might get problems if what’s been merged into master doesn’t match the original branch – e.g. if it was rebased/rewritten before merge).
3) It might be more of a hassle, but I don’t really see the fundamental problem. I’ve worked in teams on long running branches (including complete rewrites of core functionality that could not be merged to master until it’s production ready), and while re-basing was sometimes a hassle (because of the sheer complexity of the code) coordinating it in a team was never a problem.
I think that in general the problem with non-linear history in Git mostly comes from applying traditional centralized workflows to a decentralized system. I’ve worked in a code base shared by hundreds of developers, and a linear history wasn’t a problem – as long as you have the right workflows.
I’m really not a fan of rebase unless it’s me squashing a few local commits into 1.
Great article. Very useful information. thanks for the article.
I find merging rather than rebasing makes git bisect easier, not harder. In a reasonably typed language it’s very easy for a rebase to mean your previous commits no longer even compile, making bisect impossible. git bisect handles nonlinear history fine, no?
That just sounds strange. If your rebase introduces logical errors, a corresponding merge would too – there is no difference. And while git bisect may technically be able to deal with convoluted histories, it may not produce a useful result.
It’s not strange. Imagine a branch containing commits C1, C2, C3, and C4. Let’s say that C1 introduces usage of an old API, and later C3 switches from the old API to a new one. Meanwhile on master the old API is removed. Rebasing this branch onto master would render C1′ and C2′ unusable in a bisect because they cannot be compiled (the API they are trying to use no longer exists.) A merge does not have this problem.
What do you mean by bisect not producing a useful result? Linux kernel is full of merges and bisection produces useful results on a regular basis. Fix your mental model.
I see now. That’s actually a valid point. It’s hard to guarantee that every commit in a branch compiles unless you use automation to detect/enforce it (the same actually goes for merge work flows: a commit may have worked on one developer’s setup, but may fail on another setup – e.g. Mac vs Windows).
I can not recall that I have ever encountered such a situation though, and I believe that it should be quite rare if you use the recipe model.
I generally see a convoluted history as problematic when it comes to hunting down regressions or bugs. One aspect is described here.
Also, if you intend to revert whatever change introduced the bug (e.g. you need to make a release ASAP and you can delay the problematic feature to a later release), it can be much more problematic in a non-linear history to just revert a single commit (e.g. if the problem was in a conflict heavy merge commit), or the entire topic branch for that matter.
Third, if you have cross branch merging and/or cherry-picking in your history, sorting out the root cause of a problem can be non-trivial. Back when I was part of a project that was using a merge based work flow (in Perforce) I was involved in several emergency meetings where we tried to figure out what team broke what and when.
The “recipe” workflow is orthogonal to rebase vs. merge, and is entirely suseptable to the scenario I described. When your premise is a merge-based history is “convoluted”, you are doomed to reach invalid conclusions.
Again, study the Linux kernel tree. It makes *heavy* use of merge commits and each of the merged branches uses the “recipe” approach. Read the commit log messages: they are prescribing the associated code changes.
Your example of a problematic history is caused by introducing broken commits into the tree. Again, this is *entirely* orthogonal to merge vs. rebase. If you rebase commits onto master that don’t comple, same shit. Rebasing just introduces one more opportunity to introduce bugs that merges avoid.
Thanks for the article! Could you please advice me what is the best way to have a linear Git history with environment branches? For example I have development, staging and production branches. Thanks in advance!
I’m not sure about your setup, but I would assume that you have one branch where you do most of your development, and the other branches are downstream branches? In that case you should be able to keep a fairly linear history on the development branch, and just let the other branches consume changes from that branch (something like https://assets.toptal.io/uploads/blog/image/679/toptal-blog-image-1416834543418.png)
Great article. Just an update: now GitHub has the option “rebase & merge”, but unfortunately and opposed to what we (at least you and I) would want, the merge operation in this case is fast-forward.
best article I have ever read on this topic, and trust me, I have read quite a bit 😉
How long does it take you to rebase then merge? One minute? Eight minutes? Unless it’s <10s or better, atomic, someone else is going to be merging and another someone else is going to be branching in that window of time.
I go into more detail about the workflow in A stable mainline branching model for Git. In general a rebase+merge+push cycle takes less than a minute if you do it manually (especially if you rebase often and stay on top of the latest master during development). However, I recommend using some sort of merge bot for automating the process (whereby it essentially becomes “atomic”).
https://medium.com/@fredrikmorken/why-you-should-stop-using-git-rebase-5552bee4fed1
Those are valid points, especially if you have little/no automation (CI, merge bot) in a large:ish team with many inexperienced Git users. However I still believe in the recipe model, and strongly encourage people/organizations to invest the necessary time in pre-merge (to master) integration tests and Git education for developers. It pays off in the long run.
Great article. Just an update: now GitHub has the option “rebase & merge”, but unfortunately and opposed to what we (at least you and I) would want, the merge operation in this case is fast-forward.
More Technical Blogs: https://tudip.com/blogs/