A long standing misconception that dates back to the RISC vs CISC debate of the 1980’s is that CISC ISA:s yield better machine code density than RISC ISA:s. At the time that was mostly true, but today (2022) the situation is different and such claims are no longer automatically true. Let us dissect the matter…
TL;DR
Scroll to the end for the graphs 📊 …
What is code density?
Code density is a measure of how much meaningful program code can be stored in a certain amount of space. The instruction set architecture of a CPU dictates how compact the machine code is, e.g. depending on which instructions it provides and how those instructions are encoded in memory.
When does code density matter?
When discussing code density it is important to understand what impact the size of the machine code has. A few different things are directly affected by code density, some of which were more important a few decades ago than they are today, and some of which are more important in embedded systems than in workstations or servers, for instance:
- Storage size. When floppy disks and hard drives had limited storage size, even a few percent smaller code could matter. The same goes for programs that need to be stored in small ROM:s or flash memories on embedded devices.
- RAM size. When RAM was ridiculously expensive and you only had a few kilobytes of RAM, code size mattered.
- Network transfer speed / cost. When most programs consisted of program code (as opposed to large media assets) and transfer speed and costs were real issues (e.g. when loading a program over a dial-up modem line), code size mattered.
These are, however, mostly things of the past, and not something that would be strong selling points for a CPU these days.
On the other hand, there a couple of things where code density still matters today, perhaps even more so than a few decades ago:
- Cache hit ratio. Assuming equal cache sizes, denser code means that a larger chunk of a program will fit in the instruction cache, and the lower level caches (L2, L3, …) are less polluted by program code and can be used for data instead. This translates to better cache hit ratios, which in turn means faster program execution.
- Instruction fetch bandwidth. Assuming equal cache/memory bandwidths, denser code means that you will fetch more “effective work” into and out from your L1I cache on each clock cycle, which in turn means faster program execution.
Still, keep in mind that we are usually only talking about small performance advantages as a result of denser code.
Why was CISC code denser than RISC code?
The main reasons for the better code density of CISC ISA:s are (or rather, were):
- Variable length instructions. More common instructions are shorter. This utilizes the same size reducing principle as Huffman coding for instance (i.e. more frequent symbols/instructions use fewer bits than less frequent symbols/instructions). In contrast some RISC ISA:s use fixed length instructions, which means that common instructions are usually longer than the corresponding CISC instruction.
- Memory operands. By allowing most instructions to operate directly on memory operands fewer instructions are needed for manipulating variables in memory compared to RISC ISA:s, which are typically load-store architectures. This also reduces the need for having many architectural registers, which in turn reduces the size of the instruction (fewer bits are required for encoding register operands).
- Specialized registers. Many CISC architectures use specialized registers, as opposed to general purpose registers that are found in most RISC architectures. In other words some registers can only be accessed by certain instructions or for certain purposes, and some registers are even implicitly used by certain instructions without having to specify them in the instruction word. This reduces the number of bits that are required to encode register operands.
- More powerful addressing modes. Many CISC ISA:s support fairly complex addressing modes, whereas in RISC ISA:s you need to use multiple simpler instructions to calculate complex addresses. This naturally translates to fewer instructions, and hence denser code, for CISC ISA:s.
- Handwritten assembly code. Many of the CISC ISA:s were designed to be “human friendly”, and had instructions and addressing modes that made it fairly easy to write programs in assembly language instead of using a higher level language. When RISC machines came along they largely relied on compilers to do the heavy lifting of register allocation (error prone for a human) and composing more complex operations from multiple instructions. They were not meant to be programmed by hand. At this time compilers were not very good and often did not produce as compact code as a human would have done. In practice this gave CISC ISA:s an advantage in terms of code density (even if it was not as much of a technical advantage).
Clearly these are convincing arguments, and they also held true back in the day when RISC machines were new. However things have changed.
What has changed over the years?
Several things have changed over the years that have reduced or even eliminated some of the advantages of CISC over RISC, for instance:
- Less optimal CISC instruction encoding. As new instructions have been added to CISC ISA:s, new and longer instruction encodings must be used since the shorter encoding spaces have already been used up. This is especially notable for x86 that has seen several major architectural upgrades, without dropping backwards compatibility. For instance the addition of 64-bit integer arithmetic, extra registers (r8-r15) and a new floating-point paradigm (SSE2 replacing x87) has necessitated longer instruction encodings. This means that the instructions with the shortest encodings are not necessarily the most frequently used instructions anymore (in fact, several of the single-byte 8086 instructions are never used in modern x86 code).
- Compilers have improved alot. These days almost all code that a CPU runs is generated by a compiler, not a human, regardless if it is a CISC or a RISC CPU. The reason is that more often than not compilers are now better than humans at generating good machine code, and it is simply no longer worth the effort to hand-write assembly language (except for a few special cases). One effect of this is that code density for RISC machines has improved, while the code density advantage that CISC had from hand-optimized assembly code is no longer there.
- Compilers prefer RISC-style instructions. Both compilers and modern out-of-order CPU implementations tend to prefer RISC-like instructions and general purpose registers over specialized CISC constructs, which in turn has incentivized CISC CPU designers to have a RISC mindset when adding new instructions. The result is that compilers do not emit very “CISC:y” instructions that would potentially save on code size. Also, modern compilers like to inline code and allocate local variables and function arguments to registers (which is good for speed), which means that things like memory operands are not as important anymore.
- RISC ISA:s have added more powerful instructions. One of the traits of RISC ISA:s is that they have a limited instruction encoding space (whereas variable length CISC ISA:s have an almost infinite encoding space), which incentivizes RISC ISA designers to come up with clever and powerful instructions. While the early RISC ISA:s were pretty bare bones, more recent RISC ISA:s have included some interesting instructions (that never made it into CISC ISA:s for some reason). Among these are bit-field instructions that essentially do the work of 2-4 traditional bit manipulation instructions in a single instruction (as well as remove the need for traditional shift instructions), and integer multiply-and-add instructions (two instructions in one), etc. Another example is clever encoding of immediate values (numeric constants) so that most of the time you do not need to waste four bytes to represent a 32-bit numeric constant, for instance.
All in all this has eliminated much of the “CISC advantage” when it comes to code density.
Comparing code density is hard!
So let us try and compare the code density of a few different architectures, but how?
Measuring or comparing code density for different architectures can be done in many different ways, and you will get different results with different meanings.
Size of compiled programs
The naive way to measure code density is to compare the binary size of the same program when it has been compiled for two different architectures, but this has several problems, including:
- Different code may be compiled for different architectures. For instance the program may have architecture dependent optimizations or “ifdefs“.
- There may be operating-system and/or platform differences (e.g. startup code, ABI differences, third party library differences, etc).
- There may be differences in what parts of a program are statically or dynamically linked (statically linked code ends up in the program executable, while dynamically linked code does not). For instance, some parts of the standard C/C++ libraries may be statically or dynamically linked. Some parts may even be inlined by the compiler.
- There may be compiler differences. The decisions that a compiler make about optimizations etc may have a big impact on code size. Different architecture back ends of the same compiler, or even different versions of the same compiler may produce different code.
- And so on…
Dynamic code density
If we think about the effects of code density that we are interested in, i.e. instruction bandwidth and cache hit ratio, it is obvious that what we are really interested in is the dynamic code density. In other words: What code density does the L1 instruction cache see? That is very hard to measure accurately as it requires that you actually run the program, perhaps in some kind of simulator that models caches and/or reports which parts of the program are most frequently executed etc, and to compare different architectures you need to reproduce the exact same program flow on both architectures.
Twitter user Andrei F. did an interesting comparison of SPEC2006 on Apple A12 (AArch64) vs Intel 9900K (x86_64):
However, we will not go down that rabbit hole.
Hand optimized assembler programs
One way to compare the optimal code densities for different architectures is to hand-optimize selected programs by implementing them in assembly language and utilizing all the features of each ISA to the max. That way you eliminate compiler differences and inefficiencies.
A commonly cited paper, Code Density Concerns for New Architectures by Vincent M. Weaver and Sally A. McKee, took this approach (it is well worth a read).
While this approach is interesting from an academic perspective and provides lots of good information for ISA design, it is not really representative for real world program code (and it is also very hard to do a fully objective comparison this way).
Compile qualitatively selected code
What we can do is to select different pieces of fully portable code that we believe is representative for average program execution, and compile it for different architectures, without linking in platform specific dependencies etc.
To be successful we at least need to manually inspect the generated machine code to verify that the compiler has done a decent job and that there are no obvious unfair differences between the architectures that we are comparing.
This is the method of choice for this article.
Method
A few selected software programs were compiled, but not linked, using GCC. The total size of the executable sections (.text etc) was collected from the resulting object files using readelf, and the total instruction count was collected by disassembling the object files with objdump.
In an attempt to measure code density for modern CISC and RISC ISA:s, the following architectures were targeted:
| Architecture | Description |
|---|---|
| IBM z/Architecture | 64-bit CISC, variable instruction length |
| x86_64 | 64-bit CISC, variable instruction length |
| MRISC32 | 32-bit RISC, fixed instruction length |
| AArch64 (a.k.a ARM64) | 64-bit RISC, fixed instruction length |
| RISC-V RV64 (with C extension) | 64-bit RISC, variable instruction length |
There are several other ISA:s that we could have looked at (e.g. i386, MIPS, Alpha, MC68k and ARMv7), but they are simply not representative for contemporary instruction set architectures, and there are really only two contemporary CISC ISA:s that come in modern, high performance implementations (x86_64 and z/Architecture). MRISC32 is obviously the odd one here, but it was mandatory since it is my own ISA.
The following software programs were compiled for the selected architectures (they were selected based on portability, identical behavior across architectures, lack of dependencies and ease of compilation):
| Software | Description |
|---|---|
| liblz4 | Fast lossless compression library (only the library was compiled). |
| sqlite3 | SQL database engine (only library was compiled, platform specific parts were disabled). |
| mfat | Portable FAT file system library (only the library was compiled). |
| mxml | XML parsing library (only the library was compiled). |
| Quake | Game by id Software (no platform specific code included). |
GCC 12.1 was used for all architectures except MRISC32, for which GCC 13-trunk was used. The reason is that GCC 12.1 is provided by Ubuntu 22.04, while MRISC32 requires a custom fork of GCC.
The only compiler tuning flag that was used was -O3 or -O2, which are the most common optimization levels for release builds. The rationale is that we want the investigation to be representative for real world code that is normally executed on a CPU.
Relative results were generated for each software, and the results were then averaged together into a total result.
Caveats
Since the analysis was made on compiled object files without linking the programs, linker optimizations such as relaxation were not factored in. However the machine code was manually examined before and after linking to ensure that there would be no major differences.
Results
Total program size
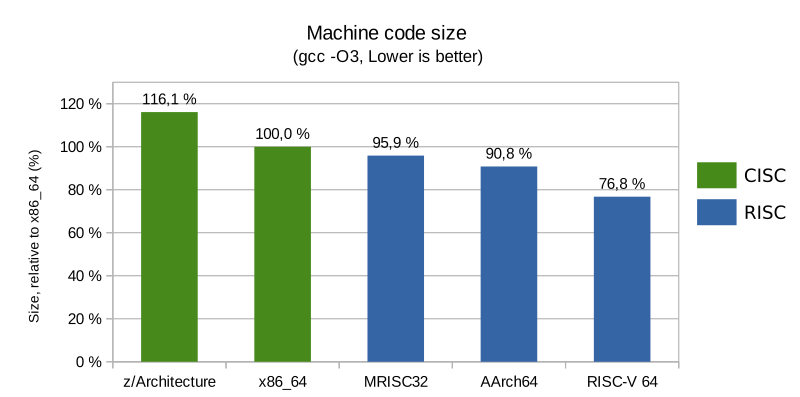
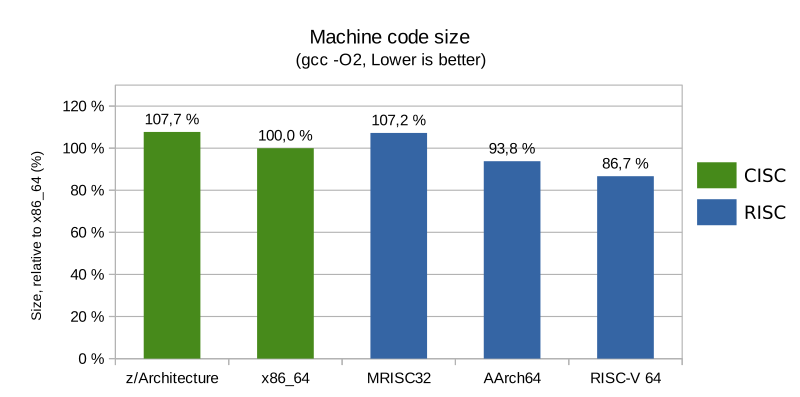
As can be seen, all RISC architectures enjoyed more compact code than CISC architectures at -O3. At -O2 AArch64 and RISC-V were more compact than both CISC architectures. The most compact code was achieved for RISC-V (with its compressed instruction extension enabled).
Total number of instructions
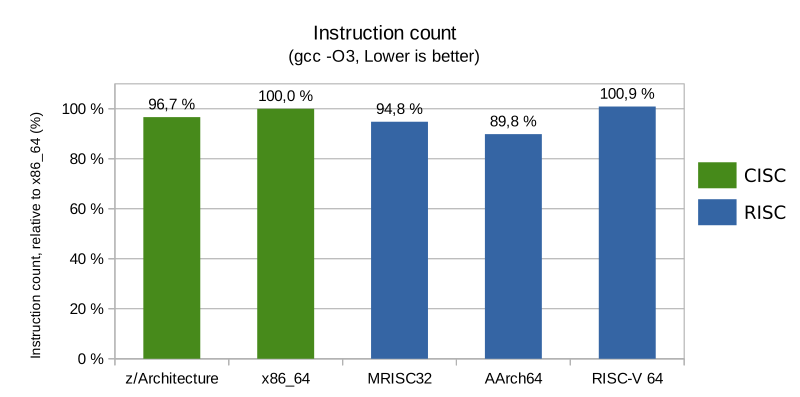
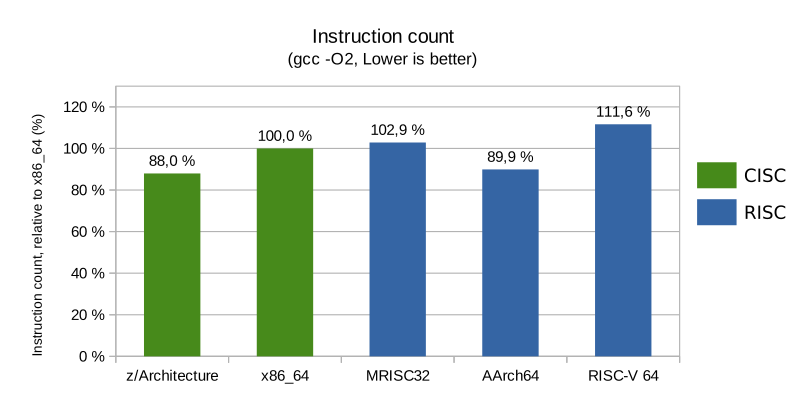
The total number of instructions was quite similar across the board at optimization level -O3, with a slight edge for RISC architectures with fixed length encodings. At -O2 things changed slightly, but AArch64 was still ahead of x86_64.
Since every CPU has an upper limit to how many instructions it can decode every clock cycle, a lower instruction count for the same amount of work is usually a performance advantage.
RISC-V required a higher number of instructions to complete the same task as the other architectures, which is to be expected because of how minimalistic its instruction set is (e.g. common addressing modes are not supported so several instructions are needed where other architectures only require one instruction). The motivation is that the front end of high performance RISC-V implementations is expected to fuse several simple instructions into more complex internal instructions. Simpler RISC-V implementations will suffer a performance penalty, though, as less actual work can be done per clock cycle.
Average instruction size
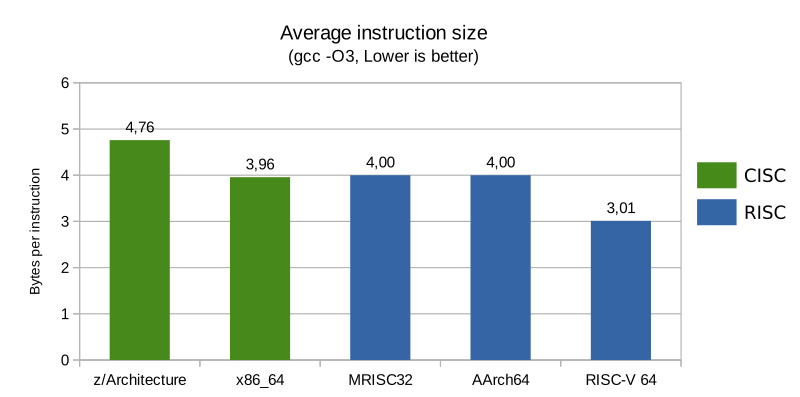
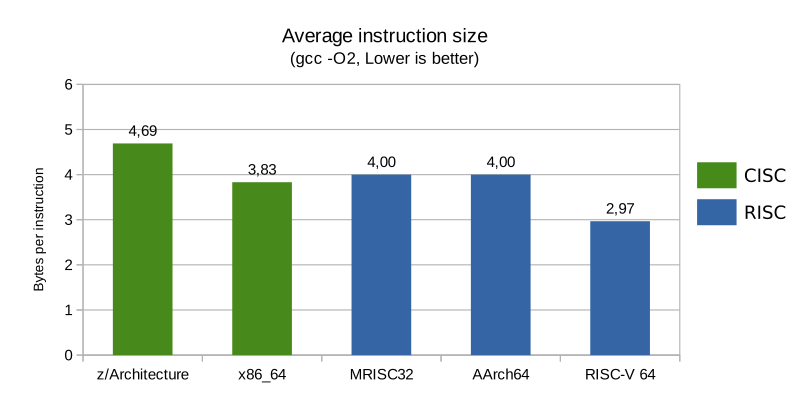
The average instruction size was about the same for x86_64 as it was for the fixed length RISC ISA:s (four bytes per instruction), regardless of optimization level, and the z/Architecture instructions were even longer (about 20% longer than AArch64 for instance). The compressed RISC-V instructions were 25% shorter than for the fixed size RISC ISA:s.
Conclusions
From the results we can conclude that for real world code that has been built with high optimization levels for modern architectures:
- CISC code is not denser than RISC code.
- CISC instructions do not perform more work than RISC instructions.
- CISC instructions are not shorter than RISC instructions.
Results are much more meaningful with -Os. This is because the compiler tries to auto-vectorise with -O3, generating really long sequences for some parts of the code. However, RISC-V does not have SIMD extensions so it does not apply there. It’s also important to know whether PIC was used or not as that affects code size, too.
The article tries to examine real world code for modern high performance architectures. -Os is not very meaningful in this context, as the vast majority of software that runs on those CPU:s are compiled with -O3 or -O2. I did update the article with -O2 numbers too.
The point about auto-vectorisation on x86 is valid, but it’s really an unfortunate side effect of the poor x86 vector ISA design (SSE/AVX was not designed to work as a general purpose loop optimizer). E.g. see the vector loop comparisons in this article: Three fundamental flaws of SIMD ISA:s.
So basically cisc should drop the x86 instruction set, like a new next generation intel cpu post i9 series, that will start only from the x64 bit instructions, or it won’t have any improvement?
Besides i think the conclusion is premature, you should have tested and compared the same code compiled for 32bit too and cisc will have worked.
So also that baggage to bring retro compatibility make sense when you don’t need strictly x64 architecture.
Plus already said if it is size to check should have compiled for optimizing size rather then performances.
Plus would have been nice at least compare also woth clang and ms vscompiler.
At the very end also a benchmark to prove the theory explained in the article based on profiling the generated code would have been helpful has the risc could have been slower even if better for some plots.
x86 can not drop backwards compatibility, ever. It’s more likely that they switch to a completely new ISA, and if/when they do that they will not make a CISC design. In many ways, x86_64 is already heavily influenced by RISC principles (many GPR:s, load/store architecture internally, etc), and a future Intel/AMD ISA would likely be more RISC than CISC.
Investigating how compact code you can get is interesting, but out of the scope of this article. If I were to write such an article I would not even include CISC ISA:s but rather pit ARM Cortex-M and RV32C against each other, since those are the ISA:s of interest in embedded systems where really tiny code size matters.
Very interesting article. However, I am wondering if comparing static instructions is the best methodology here. For instance, the compiler may unroll the loop and inline instructions, or optimize the code by guessing the branch direction while bloating the instruction on another direction. Although these optimizations are not ISA-dependent, I am not sure if compilers for different ISA may have different policies.
what about Renasis RX CISC?
Entire operating system distributions use -Os by default. Not including it here when it’s meant to measure real-world code size basically invalidates the whole takeaway from this post. Everyone knows GCC with -O2 and moreso -O3 expands things for speed that don’t need to be.
Do also include i386. While not “contemporary” it eliminates many of the problems inherent from the AMD64 extension you mentioned early on.
(I would also have loved to see MIPS o32 and n64 included… and SPARC v8 or v8+ (with branch delay slots!) and v9 (for contemporary).)
Thanks for the comments. I would also be interested in looking at more variants, but the things you suggest were out of the scope for this article (and I didn’t have time to look at all ISA:s and optimization flags etc).
Most operating system distributions are not compiled with -Os. Some kernels may be, but usually not “main stream” desktop/server kernels. OS kernels are also very special pieces of software, where most performance critical code and data structures have been hand-tuned at a very low level to ensure optimal alignment and performance etc. Furthermore, -O2 and -Os are very similar. The main difference is that -O2 enables code alignment for functions and loops (i.e. insert NOPs to make the code cache-line aligned), while -Os does not.
i386 is completely uninteresting to me. While building a new system based around i386 could be an interesting exercise it wouldn’t be a very competitive system, nor would you build your software in 32-bit mode instead of 64-bit mode just to gain performance (in fact 32-bit x86 has terrible performance compared to 64-bit x86_64, e.g. due to a very limited register file).
MIPS is pretty much dead (MIPS the company has switched to RISC-V), as is SPARC (Oracle has discontinued it, Fujitsu is shifting away from it, and SPARC/LEON is being phased out in the space industry in favor of RISC-V for instance). LoongArch (a MIPS spinoff) seems to be alive, but getting a working toolchain was not as straight-forward as for the others. And above all I didn’t want to spend lots of extra time and flood the graphs with similar RISC architectures.
Bottom line: If you’re interested in the smallest possible code size, you must also define WHY (for what purpose) you want a small code size. E.g. if it is for improved performance (e.g. higher cache hit ratio), you can not ignore all the other things that contribute to performance (e.g. the bigger register files of x86_64 and AArch64 over x86 and ARMv7, respectively, or performance gains from -O2 or -O3). If it’s for making the code fit into a small memory system, you’re probably less interested in compute performance so it would be nonsense to compare with x86_64 or s390x for instance.
Hi Marcus,
Hope you still read this thread, and terribly sorry that my post below is not related to this thread at all.
It is actually related to your online tool called “Subshifter”, but I have NOT found a separate thread dedicated to it. Also I didn’t find a way to contact you directly. My email is going to be visible to you , so feel free to email me if you want to discuss this further. Anyway, to the business related to Subshifter:
I’d like to report the bug. It’s in the “Linear Correction (beta)” part. It seems to be doing a great job, except sometimes it calculates and writes the time code, which contains …,1000 as a fraction of seconds. In other words, after calculations, the correct timecode 01:23:10,000 will be rather recorded as 01:23:09,1000 which is a non-legit subtitles time code format (to some players anyway). So, after the output file is recorded, what I have to do is to run “Search and replace”, let it find all occurrences of “,1000” string and substitute them with “,999”
I am pretty sure that you will find a better way to fix that bug in your code.
Hope I have made it clear for you.
I would appreciate if you could contact me via email to let me know when you have a chance to fix that small, but annoying bug in your Subshifter tool. Otherwise, a great job, thanks a lot, and wish you all the best with your projects!
Or you can move my post to where it should be and let me know here or in email. Thanks.
Best regards,
Denis
what about nanomips and Renasis RX CISC but both are new isa