In my previous post, The MRISC32 – A vector first CPU design, I went through some of the principles of the MRISC32 ISA. In this post I’d like to focus on scalar operations and present some of the features that set the ISA apart from others.
I have recently made some progress with a GCC back end for MRISC32, and this has made it easier to compare MRISC32 code to other architectures, such as x86, ARM and RISC-V, and some ISA design decisions have actually proven successful.
Note: In the examples below, GCC -O2 was used to generate the code. Whenever machine code is presented, the raw bytes representing the memory contents are given in hex to the left, and the corresponding assembly syntax is given to the right.
Edit: Some parts of the ISA have changed since this article was written (e.g. register names and LDI instructions). See the latest MRISC32 Instruction Set Manual.
Loading immediate values
The MRISC32 ISA has three instructions that are dedicated to loading immediate values into registers: ldi (load immediate), ldhi (load high immediate) and ldhio (load high immediate with low ones). Each instruction loads a 21-bit immediate value into a register, as shown below:

Together the three instructions enable loading a wide variety of immediate values, e.g. integers in the range -1048576 to 1048575, and bit masks such as 0x7fffffff and 0x00ff0000.
One of the more interesting aspects comes into play when you use the “high” variants to load floating point immediate values: since both integer and floating point values are stored in the same registers in MRISC32, the same instructions can be used to load integer and floating point immediate values.
By loading the high 21 bits of a 32-bit IEEE 754 floating point value, you have enough information to describe: the sign bit, the 8-bit exponent, and a 12-bit mantissa (13 effective significand bits). This means that with a single instruction it is possible to load a wide range of floating point values, including all integers in the range -8191.0 to +8191.0. In fact, as long as a number can be written as (+/-)m * 2^n, where m ∈ [4096, 8191] and n ∈ [-138, 115], it can be loaded using a single ldhi instruction.
As an example, take the following code that computes 511.9375 * x:

Analysis
Among the architectures used, only MRISC32 loads the floating point value (511.9375, or 0x43fff800 in hex notation) using a load-immediate instruction. All the other architectures will issue a data load instruction (i.e. load the floating point value via the data cache instead).
While I don’t know the implementation details of modern x86-64 CPU:s, I suspect that internally the mulss instruction will be split into a data load instruction followed by the actual multiplication instruction (making it very similar to ARMv7 in this case).
Also worth noting is that MRISC32 has the most compact code (8 bytes), while RISC-V uses up twice as much memory (16 bytes) to do the same operation. To load a full 32-bit floating point value, the MRISC32 version would require one more instruction (to OR in the lowest 11 bits of the value).
Why is this important?
Placing the immediate value directly in the instruction stream, rather than loading it using a data load instruction, has several advantages:
- The instruction operand is ready as soon as the instruction has been decoded, instead of having to wait for the result of a previous memory load instruction.
- The data cache is not polluted with instruction operands.
- You avoid a potential data cache miss.
- Code tends to be denser (instead of encoding a memory reference + the data value, you only have to encode the data value).
The min/max instructions
In every ISA that I have used, I have missed integer min/max instructions in the base instruction set (though many architectures support min and max for floating point and SIMD registers). That is one reason why I added the min, max, minu and maxu instructions to the MRISC32 ISA. However, there are a couple of reasons why they are actually necessary:
- To make vector loops efficient I needed a way to quickly determine the number of vector elements to process in each loop iteration. The min instruction elegantly solved that problem (i.e. calculate num_elements = min(number_of_elements_left, vector_register_size)).
- All SIMD ISA:s that I know of include integer min/max instructions, and for good reasons. Thus it was natural to include min/max instructions for MRISC32 vector operations. Since all instructions support both vector and scalar operands, we naturally get scalar min/max instructions “for free”.
Now, since the min and max instructions are part of the MRISC32 ISA, they can be put to good use. For instance, consider the following C code, which computes z = min(abs(x), abs(y)):
int abs_x = (x < 0 ? -x : x);
int abs_y = (y < 0 ? -y : y);
int z = abs_x < abs_y ? abs_x : abs_y;This gets translated by GCC as follows:
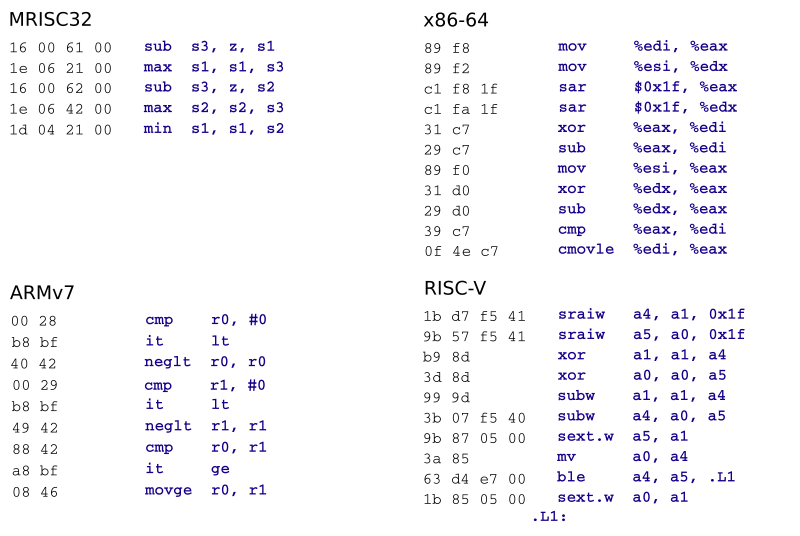
Analysis
While other architectures rely on conditional assignments or branches to solve the problem, MRISC32 can use the min/max instructions directly and:
- Perform the same task in fewer instructions.
- Avoid using/modifying the condition code (CC) register (in fact, MRISC32 does not have a condition code register at all).
- Avoid branches.
Also note that the integer min/max instructions can be used to efficiently implement operations such as abs (as shown above) and clamping/saturation.
In the x86 solution we can observe the effect of destructive operands (typical for older CISC ISA:s): since one of the source operands is also the destination operand, some extra mov instructions are needed, which is not the case for most RISC architectures (including MRISC32).
The SHUF instruction
One of my favorite instructions in the MRISC32 ISA is the shuf instruction.
The shuf instruction is really a multi-purpose instruction that can do many different things. For instance:
- Re-arrange (shuffle) bytes, e.g. swap the byte order (endianness conversions).
- Perform sign- or zero-extension, e.g. byte -> word.
- Unpacking packed data, e.g. extract the upper half-word from a word.
- Perform byte masks, e.g. y = x & 0x00ff00ff.
And of course you can do combinations of all of the above. For instance: unpack a half-word, change endianness and sign extend – all with a single instruction.
The instruction is inspired by the x86 SSSE3 PSHUFB instruction, but takes it a step further by adding the ability to sign-fill a byte slot instead of zero-filling it. One of the operands to the shuf instruction is a 13-bit word that controls the operation, so there are literally several thousands of unique operations that you can perform with it.
In a RISC ISA with limited instruction space, having a single instruction that is so versatile is very valuable.
And the best part is that it is really easy to implement in hardware (it is essentially a bit re-wiring matrix).
Unified register files
One of the more unique design choices of the MRISC32 ISA is that all registers can hold any data type, including integer values and floating point values. This brings a few advantages:
- Regardless if an MRISC32 CPU has support for floating point in hardware or not, the ABI stays the same. This simplifies many things, including compiler and operating system design.
- Many integer instructions can be reused for floating point purposes (for example loading immediate values, as discussed earlier), which reduces the number of necessary instructions in the ISA.
- There is no penalty for transferring data between floating point and integer registers, which can be beneficial in code that mixes use of integer and floating point (interpolation algorithms, video/audio codecs and 3D graphics renderers are some examples).
One more thing that I discovered is that GCC will automatically generate fairly decent code for some floating point operations, such as copysign, since it is free to use integer operations on floating point values:
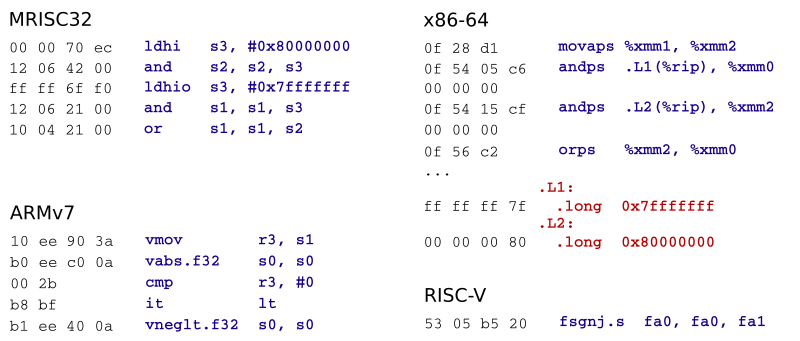
Note that the MRISC32 variant can be optimized further by using a bic instruction instead of and for clearing the sign bit, which reduces the code size by one instruction (the ldhio instruction becomes unnecessary), but still the default GCC implementation is quite OK.
The RISC-V solution fares particularly well here, since it apparently has a dedicated instruction for sign injection. Interesting. x86 on the other hand…
The RISC advantage
The MRISC32 ISA is a RISC load/store architecture, which brings several advantages common to other similar architectures (e.g. Power, MIPS, Alpha and RISC-V). Some of them are described below.
Many registers
Since there are plenty of registers to use (32 of them), many leaf functions do not need to use the stack at all. This is because up to 8 function arguments can be passed in registers (so function arguments are likely to already be in registers when a function is called), and up to 26 scalar registers can be used freely within a function scope, which reduces the probability of spilling registers to the stack (see register pressure).
For an example of a function that does not use the stack, see memcpy.S. This can be compared to an ARM implementation that needs to use the stack (since ARM does not have as many registers): memcpy.S.
Non-destructive instructions
Since all MRISC32 instructions are non-destructive, i.e. the source operands are not modified, fewer instructions are needed compared to older CISC ISA:s like x86 and 68k etc (where additional move instructions are needed here and there to get results and/or source operands into the right registers).
Consistent instruction encoding
All MRISC32 instructions are 32 bits wide. This significantly simplifies instruction fetch and decoding (the first few stages of the CPU pipeline), and also help debuggers and disassemblers as they need not guess where instructions start (e.g. disassembling ARM code can be tricky if you do not know if a certain section of code is running in Thumb mode or not, and determining where x86 instructions start and end is non-trivial).
Another important advantage is that all instructions are guaranteed to be aligned to the instruction cache line size. In other words, the CPU will never end up reading only part of an instruction from the cache (nor from any level in the memory hierarchy, for that matter), so you do not need extra logic for stitching together instructions from different cache lines, for instance.
Thanks for reading! I hope to add some more perspective on the vector parts of the MRISC32 ISA in a future post.